

前段时间我妈突然问我:儿子,爬虫是什么?我当时既惊讶又尴尬,惊讶的是为什么我妈会对爬虫好奇?尴尬的是我该怎么给她解释呢?
一、爬虫介绍
1.爬虫是什么
网络爬虫(web crawler 简称爬虫)就是按照一定规则从互联网上抓取信息的程序,既然是程序那和正常用户访问页面有何区别?爬虫与用户正常访问信息的区别就在于:用户是缓慢、少量的获取信息,而爬虫是大量的获取信息。

这里还需要注意的是:爬虫并不是Python语言的专利,Java、Js、C、PHP、Shell、Ruby等等语言都可以实现,那为什么Python爬虫会这么火?我觉得相比其他语言做爬虫Python可能就是各种库完善点、上手简单大家都在用,社区自然活跃,而社区活跃促成Python爬虫慢慢变成熟,成熟又促使更多用户来使用,如此良性循环,所以Python爬虫相比其他语言的爬虫才更火。
下面是一段hello world级别的Python爬虫,它等效于你在百度搜索关键字:python。
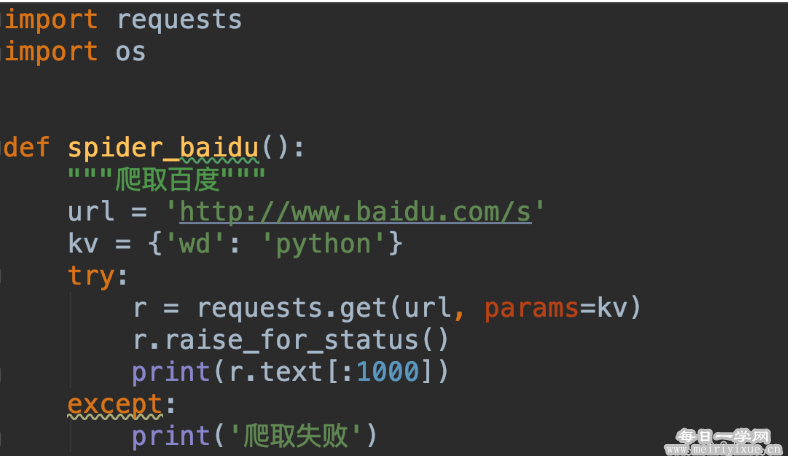
2.爬虫案例
既然爬虫是大量抓取网页,那是不是爬虫都是不好的呢?答案当然不是,可以说我们的日常上网已经离不开爬虫了,为什么这么说?下面我就为大家盘点几个爬虫日常应用:
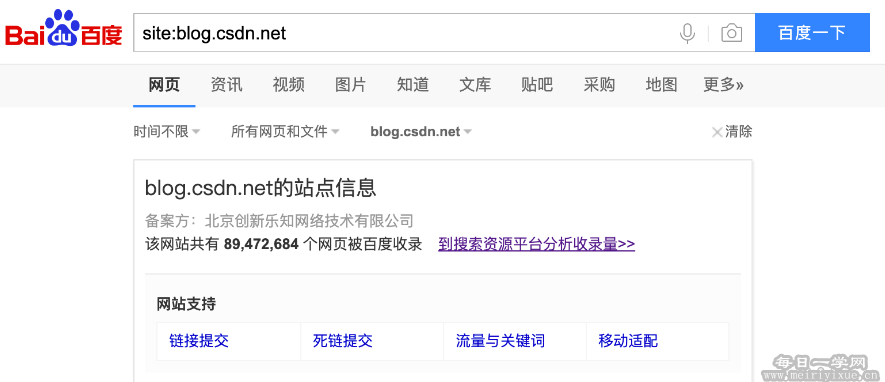
搜索引擎:如Google、百度、雅虎、搜狗、必应等等很多搜索引擎其本质就是一个(可能多个)巨大爬虫,这些搜索引擎工作原理是:页面收录->页面分析->页面排序->响应关键字查询,也就是说它会先把互联网上很多页面保存到服务器,然后分析网页内容建立关键字索引,最后用户输入关键字的时候去查询内容,然后根据相关性排序(百度害人的竞价排名毫无相关性可言),第一步的页面收录就是爬虫,百度查看一个网站有多少网页被收录方法,百度输入:site:你想查询的网站,如:site:blog.csdn.net。
抢票软件:很多人在吐槽12306卡,可你不知道12306几乎每天都相当于淘宝双11的流量,这谁受得了。为什么每天都是如此高的流量?答案自然是爬虫了,为什么抢票软件可以抢票?因为它在不断的刷新和监控是否有余票,大大小小这么多抢票app,访问量之高可想而知。之前很多公司都出过抢票插件,如:百度、360、金山、搜狗等等,后来都被铁道部约谈下线了,而现在又流行抢票app,为什么抢票app可以,插件就不可以?可能是因为管理和可控性的原因。
二、爬虫的价值
从上面举的几个例子来看,爬虫对整个互联网的价值真的无法估量,那对于小我而言,爬虫能给我们带来哪些价值?
1.隐形的翅膀
如果你问我学完Python基础之后该学习什么技能?我会毫不犹疑的说爬虫,为什么是爬虫?
爬虫相对其他技能简单易学,且效果立即可见,会有一定的成就感
爬虫可以说是其他技能的基石,因为他是数据的来源,现在这个时代谁有数据谁才能称王,所以会爬虫绝对会让你如虎添翼
在国内,很多企业巴不得你啥都会,所以在应聘时,爬虫会是一个不错的加分项
2.看不见的商战
职场对话:
老板:小明给你个重要任务。 小明:就算996我也在所不辞(第一次接到老板的直接需求)! 老板:你能不能搞到竞争对手的商品价格? 小明:没问题(牛逼先吹出去),小事! 老板:这可不是小事,只要你能持续获取竞品价格,我们就可以标价低于他们一点点,持续如此大家就知道我们的价格肯定是比他们低,这样大家就直接来我们这里购买商品了,到时候庆功宴上你就是最大功臣(先画个饼)。 小明:老板牛逼,老板英明!
3.会爬虫就可以创业
工作之后很多同学会利用上班空余时间,来做自己的东西或者项目,别看开始是一个小打小闹的东西,慢慢丰富将来也许会成为一款成熟的产品。
而爬虫可以让你很轻松的实现自己的产品,做的好的话就可以创业。这里猪哥给大家列几个简单的创业项目,当然作为一个思维引导。
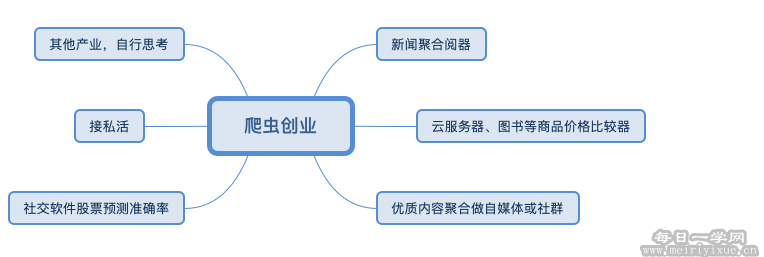
如果你想做一款好的产品,你需要从用户需求出发去思考,做解决目前存在的问题的产品或者目前还没有的服务,也许你的产品就是下一个头条。
三、盗亦有道
爬虫既然如此强大而优秀,那是不是会了爬虫就可以为所欲为?
延伸话题:其实我内心一直有一个疑问:为什么互联网公司都偏爱用动植物来命名或作为logo?如:蚂蚁金服、天猫、菜鸟、金东狗、腾讯企鹅,百度的熊掌、搜狗、途牛、美团的袋鼠。。。真的是太多了,难道仅仅是因为好记?我认为好记是一个原因,其根本原因是受到编程行业的影响,你想想编程行业有多少动植物:Java(咖啡)、Python(蟒蛇)、Go(囊地鼠)、PHP(大象)、Linux(企鹅)、Perl(骆驼)、Mysql(海豚)等等,具体为什么编程行业喜欢用动植物这猪哥就不清楚,还请明白的同学留言告知大家!
讲上面的延伸话题想表达的是,大自然世间万物,相生相克,衡而不祸!而爬虫也是如此,下面就为大家介绍一下约束爬虫的几个点。
1.robots协议
做过网站的同学也许知道,我们在建站的时候需要在网站根目录下放一个文件:robots.txt,这个文件是干什么用的呢?
Robots协议,也称为爬虫协议、机器人协议等,其全称为“网络爬虫排除标准(Robots Exclusion Protocol)”。网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。
每个网站的根目录下都必须放置robots.txt文件,否则搜索引擎将不收录网站任何网页。
下面我们以百度为例子,来看看百度的robots.txt文件:

我们在百度robots协议的最下面,有这样一条:
User-agent: * Disallow: /
这表示除上面那些定义过的爬虫以外其他爬虫都不允许爬取百度任何东西!
2.法律
我们都知道在发起请求时User-agent是可以自定义的,也就是说我们可以绕过robots协议和以User-agent来定义的反爬虫技术,所以robots协议可能更像一个君子协议,那咱们国家有没有法律明文规定呢?我们来了解一下非法侵入计算机信息系统罪:
第二百八十五条 非法侵入计算机信息系统罪:违反国家规定,侵入前款规定以外的计算机信息系统或者采用其他技术手段,获取该计算机信息系统中存储、处理或者传输的数据,或者对该计算机信息系统实施非法控制,情节严重的,处三年以下有期徒刑或者拘役,并处或者单处罚金;情节特别严重的,处三年以上七年以下有期徒刑,并处罚金。
我们可以看到重点信息:入侵计算机获取数据是违法的,也就是说爬虫技术本身是无罪的,因为它是获取的公开信息,并未非法入侵计算机。但是如果你用爬取到的数据去从事商业化操作,那也许就构成了违法犯罪行为!
给大家介绍下因爬虫而被判刑的案件:
头条爬虫官司:https://dwz.cn/qBBHc2fq
酷米客公司官司:https://dwz.cn/9IpAOHGB
360和百度爬虫官司:https://dwz.cn/RGRa3HJc
我发现这几起案件的通性有两点:1、公司性质。2、竞争对手。3、让人家找到线索。
最后提醒大家:技术人,要守住自己的底线,违反国家法律法规的事情咱们坚决不能做!
3.反爬虫工程师
本来想采访一位携程反爬虫工程师,但是他说由于工作保密原因不便接受采访,所以只好尊重他的选择!
四、爬虫现状
之前猪哥说过互联网中有超过50%的流量来自爬虫,那我们就来简单聊聊目前爬虫的现状吧!
1.技术
反爬虫几乎和爬虫同时诞生,它们是相爱相杀的连个技术,如果没有爬虫就没有反扒,而反扒技术又反过来又可以促进爬虫技术的发展。
交互问题:各种变态的验证码充斥,尤其是12306,分分钟都想爆粗口,以后会越来越变态。。。
js加密:最近很流行的一种反扒技术,会爬虫还得先学js,然后反爬虫工程师在js里面各种投毒,杀人诛心。。。
IP限制:限制单个ip某段时间内访问次数
猪哥只介绍了一个反扒技术,当然都有现成的技术解决,但是作为爬虫员最重的并不是会使用工具或框架去应对反扒,而是能通过自己的思考和摸索破解反扒,因为反扒技术更新快且多样化。
2.就业
就业的话主要从招聘、薪资、就业形势三个方面分析,我从网上查阅了一些资料,然后整理以图片形式提供给大家参考。
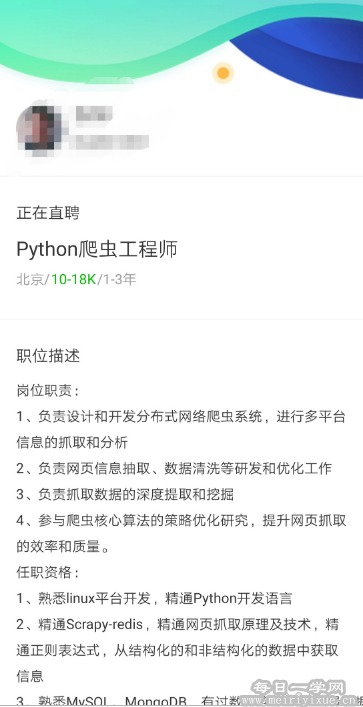
数据来源:职友集:https://dwz.cn/6PeU46QY
3.前景
现在很多人并不看好爬虫的前景,只搞爬虫的话技术只停留在当前水平,不再学习新知识,不再进步的话,那么是没有前途的,总有一天会被时代淘汰,其实其他职位也只如此。
每个职业都是有一个横向和纵向的发展,也就是所谓的广度和深度的意思。第一、如果专研得够深,你的爬虫功能很强大,性能很高,扩展性很好等等,那么还是很有前途的。第二、爬虫作为数据的来源,后面还有很多方向可以发展,比如可以往大数据分析、数据展示、机器学习等方面发展,前途不可限量,现在作为大数据时代,你占据在数据的的入口,还怕找不到发展方向?所以爬虫也许只是一个起点一个跳板,是你走向人生巅峰的一个基石,总有一天你会迎娶白富美!





还没有评论,来说两句吧...